
經過昨天的檔案操作後
想要帶大家更更進階的操作~

根據工作中大大的要求大概可以定義成這兩項技能
會拆解成兩大項:1.資料的處理 2.文件的處理
不過我們都學python了~
當然要把這些功能發揮到極限
| 操作類別 | Excel | Python |
|---|---|---|
| 數據清理 | 使用內建功能(如去重、填充缺失值) | 使用 Pandas 庫進行靈活的數據清洗和處理 |
| 篩選數據 | 透過篩選功能快速篩選特定數據 | 使用條件過濾(如 df[df['column'] > value]) |
| 合併數據 | 使用 VLOOKUP 或合併功能 | 使用 Pandas 的 merge() 方法 |
| 計算 | 基本公式(如 SUM、AVERAGE) | 使用 Pandas 和 NumPy 進行複雜計算 |
| 拆分數據 | 手動拆分或使用文本分列功能 | 使用 groupby() 和 to_csv() 進行自動化處理 |
| 文件格式處理 | 批次修改工作表名稱較為繁瑣 | 使用 openpyxl 或 Pandas 輕鬆批量處理 |
| 合併文件 | 合併多個文件需要手動操作 | 使用 pd.concat() 自動合併多個文件 |
| 拆分文件 | 條件拆分文件需手動操作 | 使用條件判斷和循環自動化拆分文件 |
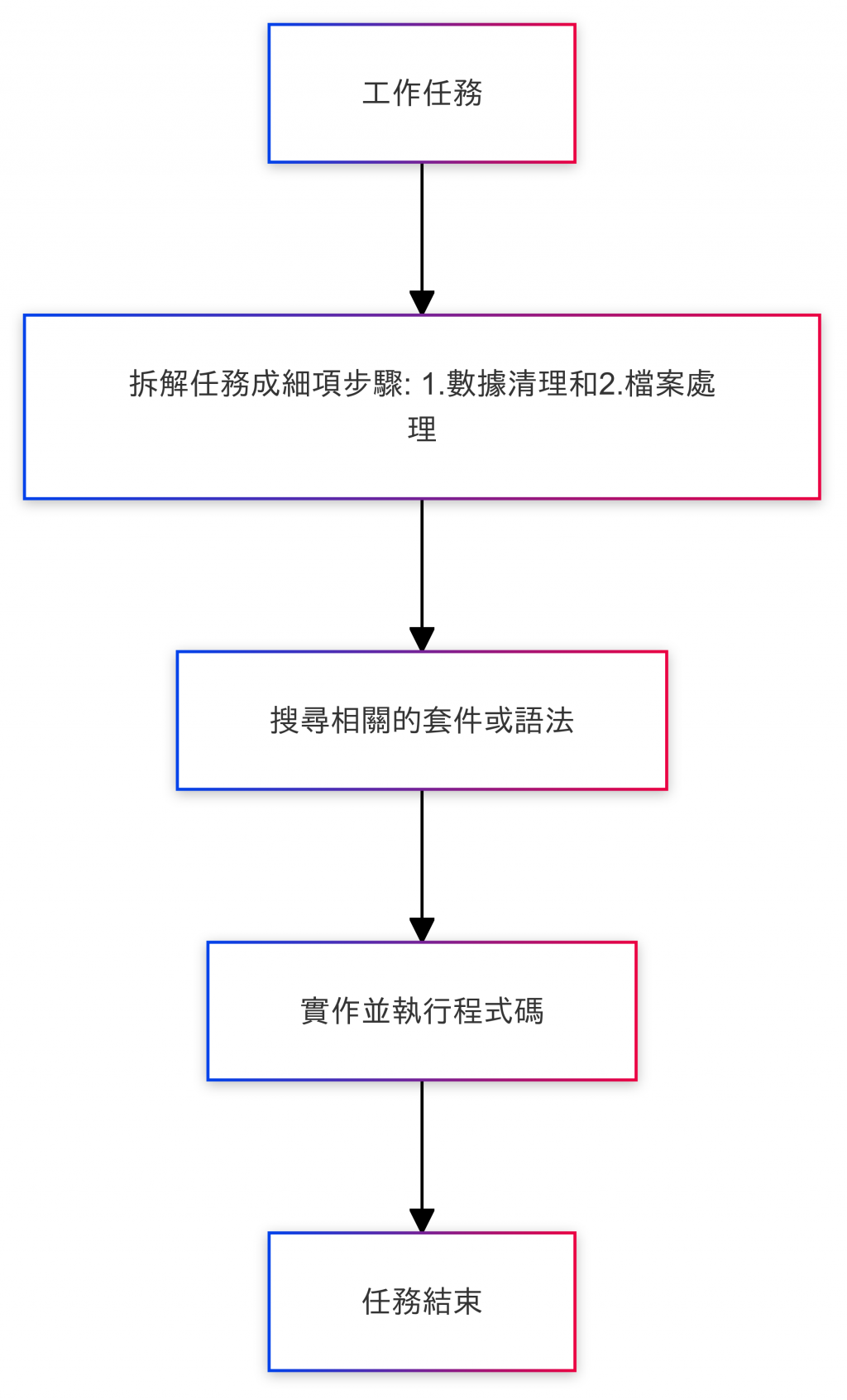
我比較傾向於這種方式來實作帶語法~
應該要先從目標->拆解->找工具或語法->實作->結案
這種方式來學習程式~
否則使用每次學新東西
就要把整本document看完或一行一行demo每個功能
有點本末倒置學習程式的目的
本來是希望透過程式解決問題,結果自己問題更多了!?
於是我們可以透過時序圖來看是怎麼樣釐清這個流程的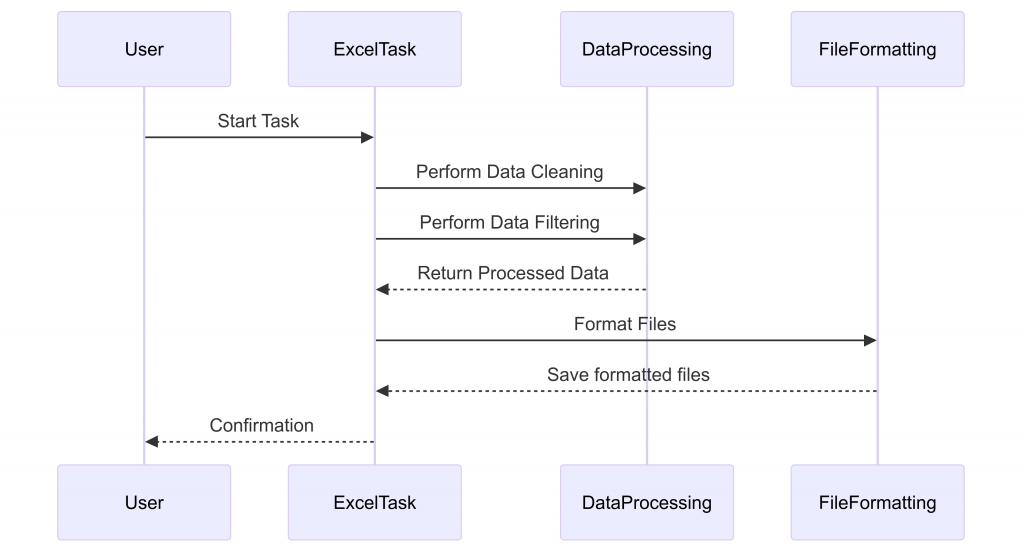
tips - 時序圖的好處1.可以呈現交互應用的案子: 以垂直的時間線展示系統中各對象之間的消息交換,讓開發者和設計者能夠清楚地看到系統中的邏輯流程。2.適合複雜場景:多個對象需要頻繁交換消息的情境(例如用戶請求和伺服器回應)
流程圖比較適合程式或行動的單純邏輯判斷步驟,時序圖在交互處理的時間線上可以更好的描述
會依照上面的架構來分兩個parts
| 任務類型 | 具體操作 | 使用場景 |
|---|---|---|
| part1數據處理 | ||
| 資料清理 | 移除重複 | 移除重複、處理遺失數據、標準格式、移除不必要欄位 |
| 資料篩選 | 篩選資料 | 篩選特定欄位、篩選特定值 |
| 合併資料 | 合併數據 | 多筆資料合成總表 |
| 計算 | 數據計算 | 基本的數據加減乘除、sum、average、count、日期加減 |
| 拆分數據 | 分割總表 | 總表拆分成各表數據資料 |
| part2文件格式處理 | ||
| 批次修改 | 修改 sheet 名稱 | 批次修改 sheet 名稱 |
| 文件合併 | 合併文件 | 合併多個文件到一份 Excel |
| 文件拆分 | 拆分文件 | 把總表依照特定條件拆分成多個文件 |
| 重新命名 | 修改 sheet 名稱 | 重新命名 sheet |
需求:
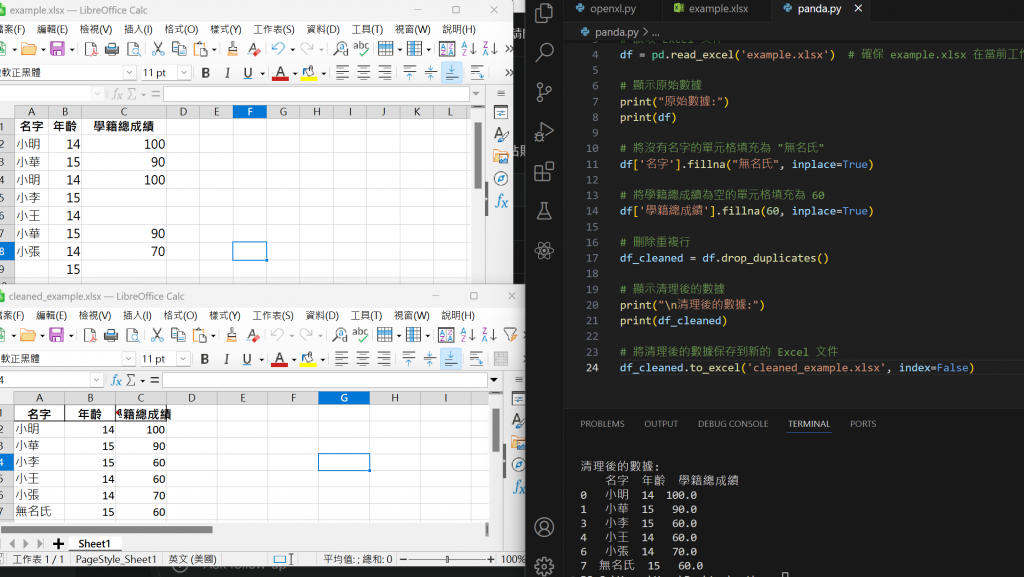
老師在學校一定很常遇到沒名字的人或是成績不小心空格。
這時候範例程式就是要處理這些值
無名氏
| 名字 | 年齡 | 學籍總成績 |
|---|---|---|
| 小明 | 14 | 100 |
| 小華 | 15 | 90 |
| 小明 | 14 | 100 |
| 小李 | 15 | |
| 小王 | 14 | |
| 小華 | 15 | 90 |
| 小張 | 14 | 70 |
| 15 |
import pandas as pd
# 讀取 Excel 文件
df = pd.read_excel('example.xlsx') # 確保 example.xlsx 在當前工作目錄中
# 顯示原始數據
print("原始數據:")
print(df)
# 將沒有名字的單元格填充為 "無名氏"
df['名字'].fillna("無名氏", inplace=True)
# 將學籍總成績為空的單元格填充為 60
df['學籍總成績'].fillna(60, inplace=True)
# 刪除重複行
df_cleaned = df.drop_duplicates()
# 顯示清理後的數據
print("\n清理後的數據:")
print(df_cleaned)
# 將清理後的數據保存到新的 Excel 文件
df_cleaned.to_excel('cleaned_example.xlsx', index=False)
tips - panda語法解釋
1. 填充值
DataFrame.fillna(value=None, method=None, axis=None, inplace=False)
df['名字'].fillna()這個意思,是把資料即透過名字的索引來把名字那個垂直資料(column)都做處理
df['名字']: 這部分表示從 DataFrame df 中選取名為 '名字' 的列。這個列的所有數據都會被提取出來,並形成一個 Series 對象。
2. 重複值刪除
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
刪除重複值有許多參數,不過直接使用df.drop_duplicates()可以row中重複的值刪除整個row(水平資料)
如果有不清楚文件資料的方向(row,column)可以看昨天的說明喔~!!
測試
接下來步驟一做完了
我們會進行篩選的動作
目標是把超過90分的同學拉出來表揚(print就好)
import pandas as pd
# 讀取 Excel 文件
df = pd.read_excel('cleaned_example.xlsx') # 確保 cleaned_example.xlsx 在當前工作目錄中
# 篩選學籍總成績大於90的數據
high_scores = df[df['學籍總成績'] > 90]
# 打印學籍總成績大於90的數據
print("學籍總成績大於90的數據:")
print(high_scores)
tips - 判別式篩選(tip3超重要!!!)
1.內層的df: DataFrame df 的列進行索引,返回的是一個 Series,這個 Series 包含了 學籍總成績 列中的所有值,透過判別式處理是否符合條件。
2.外層的df: df[...]:這部分使用了布林索引,將內層生成的布林 Series 作為索引來篩選原始 DataFrame df 中的行。這樣做會返回一個新的 DataFrame,其中僅包含滿足條件(學籍總成績大於 90)的行。
3.如果省略外層的df? => panda就不會把那個水平row的資料撈出來,只會把運算完布林值的Series印出來
今天假設有一個學生叫做roni的學生轉來
我們要新增他的資料
import pandas as pd
# 讀取已處理的 Excel 文件
df = pd.read_excel('cleaned_example.xlsx') # 確保 cleaned_example.xlsx 在當前工作目錄中
# 新增的班級成員
new_student = pd.DataFrame({
'名字': ['roni'],
'年齡': [15],
'學籍總成績': [100]
})
# 將新學生資料添加到原有 DataFrame
df = pd.concat([df, new_student], ignore_index=True)
# 打印合併後的結果
tips
pd.DataFramer建立一筆有索引的資料
多個 DataFrame 沿著指定的軸進行合併
今天我要計算這個班級的成績平均值可以透過熊貓的mean處理
import pandas as pd
# 讀取已處理的 Excel 文件
df = pd.read_excel('cleaned_example.xlsx') # 確保 cleaned_example.xlsx 在當前工作目錄中
# 計算學期總成績的平均值
average_score = df['學籍總成績'].mean()
# 打印平均成績
print(f"班級的學期總成績平均為: {average_score:.2f}")
tips
fstring 的進階功能 : 變數+冒號+.數字f : 數字可以控制顯示小數點後的幾位數今天如果依照剛剛的表格我們想要分類表格可以這樣看
import pandas as pd
# 讀取已處理的 Excel 文件
df = pd.read_excel('cleaned_example.xlsx') # 確保 cleaned_example.xlsx 在當前工作目錄中
# 按年齡分組
grouped = df.groupby('年齡')
# 分別印出14歲和15歲的同學資料
print("14歲的同學:")
print(grouped.get_group(14))
print("\n15歲的同學:")
print(grouped.get_group(15))
tips
14歲的學生
| 名字 | 年齡 | 學籍總成績 |
|---|---|---|
| 小明 | 14 | 100 |
| 小王 | 14 | 60 |
| 小張 | 14 | 70 |
15歲的學生
| 名字 | 年齡 | 學籍總成績 |
|---|---|---|
| 小華 | 15 | 90 |
| 小李 | 15 | 60 |
| 無名氏 | 15 | 60 |
import pandas as pd
# 生成示範數據
data = {
"數據1": [1, 2, 3, 4, 5],
"數據2": [5, 4, 3, 2, 1]
}
# 建立 Excel 檔案並添加工作表
with pd.ExcelWriter('示範檔案.xlsx', engine='openpyxl') as writer:
for month in ["1月", "2月", "3月"]:
# 創建 DataFrame
df = pd.DataFrame(data)
# 將 DataFrame 寫入工作表
df.to_excel(writer, sheet_name=month, index=False)
print("示範 Excel 檔案已生成,包含工作表: 1月, 2月, 3月")
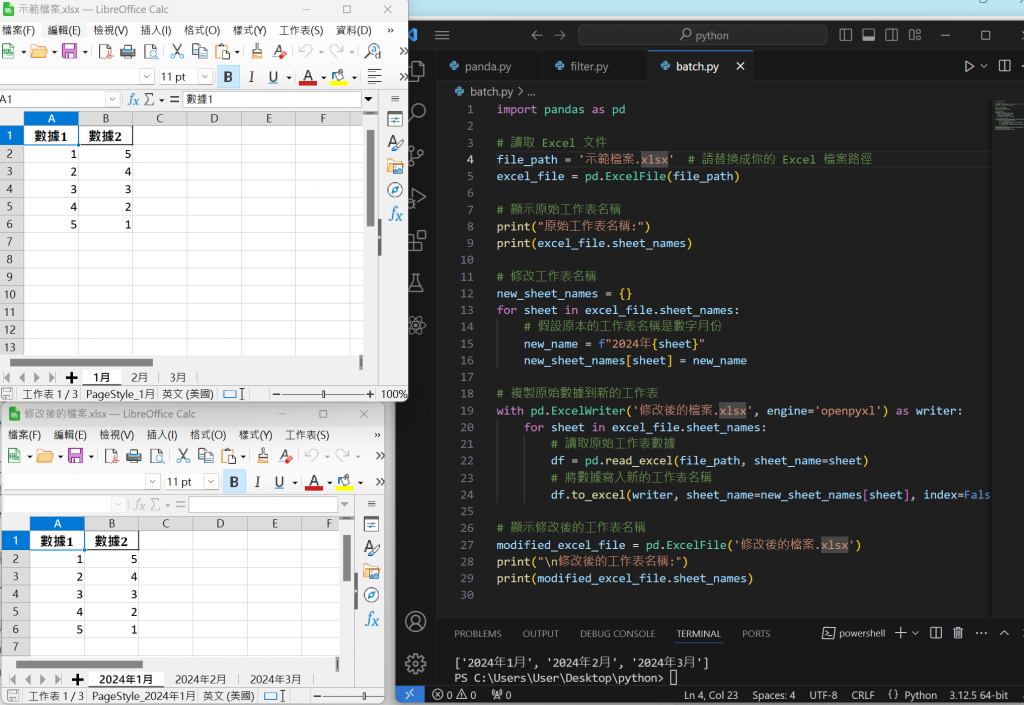
我們可以透過panda先產生一個基本數據
import pandas as pd
# 讀取 Excel 文件
file_path = '示範檔案.xlsx' # 請替換成你的 Excel 檔案路徑
excel_file = pd.ExcelFile(file_path)
# 顯示原始工作表名稱
print("原始工作表名稱:")
print(excel_file.sheet_names)
# 修改工作表名稱
new_sheet_names = {}
for sheet in excel_file.sheet_names:
# 假設原本的工作表名稱是數字月份
new_name = f"2024年{sheet}"
new_sheet_names[sheet] = new_name
# 複製原始數據到新的工作表
with pd.ExcelWriter('修改後的檔案.xlsx', engine='openpyxl') as writer:
for sheet in excel_file.sheet_names:
# 讀取原始工作表數據
df = pd.read_excel(file_path, sheet_name=sheet)
# 將數據寫入新的工作表名稱
df.to_excel(writer, sheet_name=new_sheet_names[sheet], index=False)
# 顯示修改後的工作表名稱
modified_excel_file = pd.ExcelFile('修改後的檔案.xlsx')
print("\n修改後的工作表名稱:")
print(modified_excel_file.sheet_names)
tips
1.with pd.ExcelWriter('修改後的檔案.xlsx', engine='openpyxl') as writer:
這個函數用於創建一個 Excel 檔案寫入器,並指定生成的檔案名稱 '修改後的檔案.xlsx'。2.for sheet in excel_file.sheet_names:
3.df.to_excel(writer, sheet_name=new_sheet_names[sheet], index=False)
這段程式碼的作用是:
這邊批次順便把修改sheet demo一起做掉了
我們可以在成績那個資料夾底下新增classed_file
並且把剛剛的cleandata複製一份
變成ClassA跟ClassB
class B 新增兩名同學
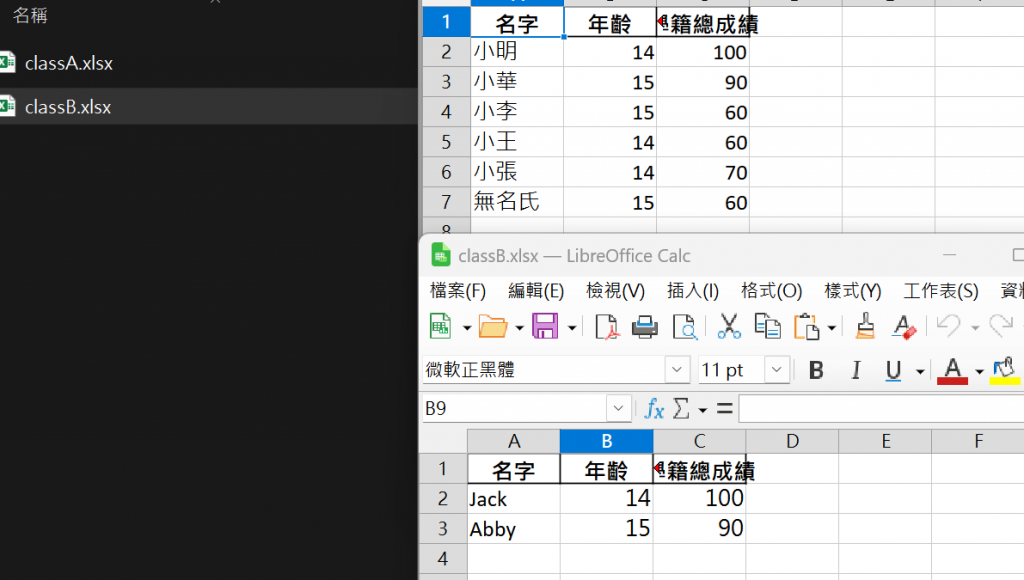
接者我們就要把這個資料夾底下的同學資料整合成總表
import pandas as pd
import os
# 設定資料夾路徑
folder_path = 'classed_file' # 資料夾名稱
# 創建一個空的列表來存儲所有的 DataFrame
all_dataframes = []
# 遍歷資料夾中的所有 Excel 檔案
for filename in os.listdir(folder_path):
if filename.endswith('.xlsx'):
file_path = os.path.join(folder_path, filename)
# 讀取 Excel 檔案並將其添加到列表中
df = pd.read_excel(file_path)
all_dataframes.append(df)
# 使用 concat 合併所有 DataFrame
combined_df = pd.concat(all_dataframes, ignore_index=True)
# 將合併後的 DataFrame 保存為新的 Excel 檔案
combined_df.to_excel('成績總表.xlsx', index=False)
print("所有學生成績已成功合併並保存為 成績總表.xlsx")
確保所有 Excel 檔案具有相同的列結構,以便能夠正確合併。
如果您需要處理特定工作表,可以在 pd.read_excel() 中指定工作表名稱,例如:pd.read_excel(file_path, sheet_name='Sheet1')。
目標是要依照年齡把14、15歲的學生拆成兩張表
import pandas as pd
# 讀取已處理的 Excel 文件
df = pd.read_excel('cleaned_example.xlsx') # 確保 cleaned_example.xlsx 在當前工作目錄中
# 按年齡分組
grouped = df.groupby('年齡')
# 將 14 歲的學生資料保存到 Excel 檔案
df_14 = grouped.get_group(14)
df_14.to_excel('students_age_14.xlsx', index=False)
# 將 15 歲的學生資料保存到 Excel 檔案
df_15 = grouped.get_group(15)
df_15.to_excel('students_age_15.xlsx', index=False)
print("已將學生資料依年齡分組並保存為兩個 Excel 檔案。")
tips
抱歉今天的東西有點多
但是我不希望把這些順序跟項目拆掉~
所以花了點時間打了
如果看不完可以分part1 part2來看
今天我們學會了兩大操作1.表格文件資料處理2.表格文件的操作處理
相信大家在經過今天的洗禮後應該更可以應對老闆的要求了!?


 iThome鐵人賽
iThome鐵人賽